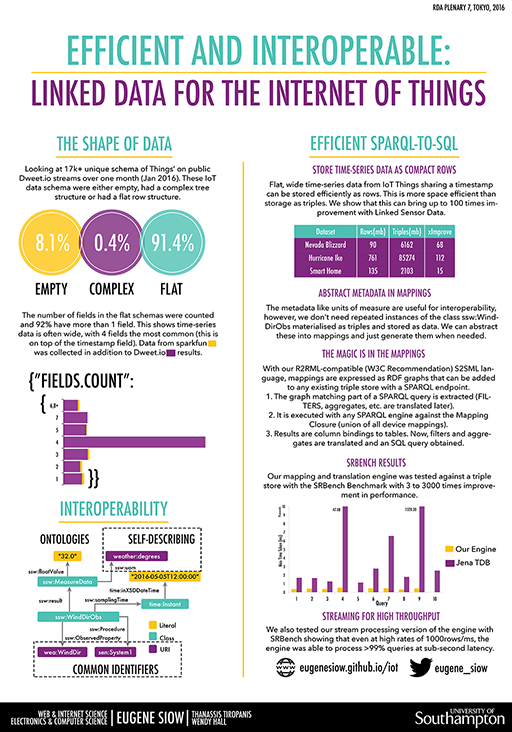
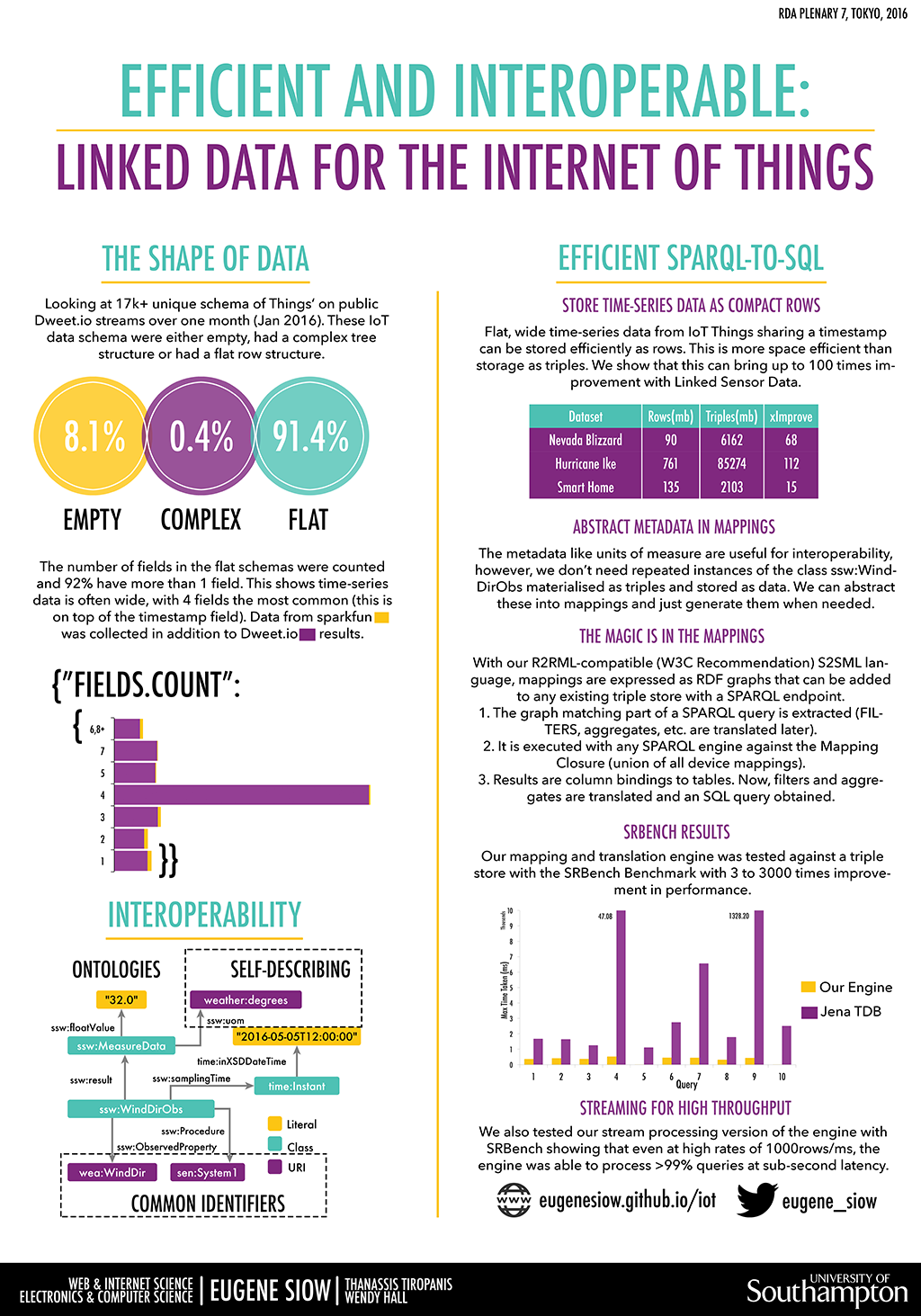
Poster Abstract
Internet of Things (IoT) applications and services need data, which is collected from distributed and heterogeneous sensors, to be aggregated, integrated and interpreted in the context of other sources of information. Linked Data can facilitate this through the use of common identifiers, ontologies and self-describing semantics. However, storing sensor data as Linked Data is inefficient in terms of storage and query performance which is further exacerbated by the resource constraints of compact devices & hubs that are deployed in close proximity to sensors to perform this integration. We investigate the structure of data produced by sensors in the Internet of Things and suggest how these time-series data can be advantageously stored in relational databases and streams and queried efficiently using SPARQL-to-SQL translation. We present our implementation which can utilise any current SPARQL engine to process both mappings and graph matching to produce efficient SQL queries. We show how this improves the performance results using an established benchmark and is equipped to handle high loads with a streaming engine.
Event Information
I received a scholarship for Early Career Researchers to attend and present at the Research Data Alliance (RDA) Plenary 7 in Tokyo, Japan. The RDA is an organisation that builds the social and technical bridges that enable open sharing of data. I presented about how Linked Data can be a technical bridge for encouraging inter-operability among silos of Internet of Things data.
It was an interesting and enriching experience as I had the opportunity to serve as the secretary for a working group on Permanent Identifiers and a birds of the feather session on data search. I also managed to attend and contribute to working group sessions on big data and research repositories.
Of course, beautiful Tokyo and the wonderful ramen, sushi and other Japanese cuisine added to the experience. It brought back memories of the backpacking trip and the other times in Japan.



{kind=link}